ایندکس صفحات چه ربطی به فایل robots.txt دارد؟ کشف، خزیدن و ایندکس چگونه کار می کنند؟ فایل robots.txt چیست؟ چه چیزی باعث خطای Indexed, though…





خطای Blocked by robots.txt و Indexed, though blocked by robots.txt دو وضعیت در گوگل سرچ کنسول هستند که نشون میدن صفحه خزیده نشده بخاطر اینکه توی فایل robots.txt خزیدن رو برای ربات گوگل مسدود کردید.
اما تفاوت بینشون اینه که:
❌با «Blocked by robots.txt»، صفحات شما در گوگل ظاهر نمیشن،
❌اما در خطای “Indexed, though blocked by robots.txt,” میتونید URL های تحت تاثیر رو در نتایج جستجو مشاهده کنید، حتی اگر اونها با دستورالعمل Disallow در robots.txt شما مسدود شده باشند.
❌ به عبارت دیگه Indexed, though blocked by robots.txt به این معنیه که گوگل صفحه شما رو نخزیده اما با این وجود ایندکسش کرده.
رفع این مشکلات یعنی که باید استراتژی خزیدن و ایندکس بهینه داشته باشید. حالا بریم ببینم چجوری باید تجزیه و تحلیلش کنید و چجوری میتونید این خطا رو از بین ببرید.
فهرست:
- ایندکس صفحات چه ربطی به فایل robots.txt دارد؟
- فایل robots.txt چیست؟
- چه چیزی باعث خطای Indexed, though blocked by robots.txt در گوگل سرچ کنسول میشود؟
- چرا Indexed, though blocked by robots.txt برای سئو سایت بد است؟
- روش رفع خطای Indexed, though blocked by robots.txt در گوگل سرچ کنسول
- خطای Blocked by robots.txt در گوگل سرچ کنسول یعنی چه؟
- روش رفع خطای Blocked by robots.txt
- جمع بندی
ایندکس صفحات چه ربطی به فایل robots.txt دارد؟
درسته که رابطه بین فایل robots.txt و فرآیند ایندکس ممکنه گیج کننده باشه، اما وقتی کامل درکش کنید، راحتتر میتونید این خطا رو در گوگل سرچ کنسول برطرف کنید.
کشف، خزیدن و ایندکس چگونه کار می کند؟
قبل از اینکه یه صفحه ایندکس بشه، خزنده های موتورهای جستجو باید ابتدا اون رو کشف کنند و بخزند.
در مرحله کشف، خزنده متوجه میشه که یه URL مشخص وجود داره. در حین خزیدن، ربات گوگل از اون URL بازدید میکنه و اطلاعاتی در مورد محتواش جمع آوری میکنه. پس از اون URL به برای ایندکس شدن فرستاده میشه و میتونه در میان سایر نتایج جستجو قرار بگیره.
این روند همیشه همینقدر آسون نیست. میتوانید با خواندن این مقالات در موردش اطلاعات بیشتری کسب کنید:
⚡حل مشکل Discovered-currently not indexed گوگل سرچ کنسول
⚡حل مشکل Crawled-currently not indexed گوگل سرچ کنسول
فایل robots.txt چیست؟
Robots.txt فایلیه که میتونید ازش برای کنترل نحوه خزیدن ربات گوگل در وب سایت خودتون استفاده کنید. هر زمان که دستور Disallow رو در اون قرار میدید، ربات گوگل میدونه که نمیتونه از صفحاتی که این دستورالعمل رو دارند بازدید کنه.
اما robots.txt نمیتونه ایندکس رو کنترل کنه.
برای دستورالعمل های دقیق در مورد اصلاح و مدیریت فایل، به راهنمای ما در مورد robots.txt مراجعه کنید.
چه چیزی باعث خطای Indexed, though blocked by robots.txt در گوگل سرچ کنسول میشود؟
گاهی اوقات گوگل تصمیم میگیره یه صفحه کشف شده رو با وجود اینکه نمیتونه اون رو بخزه و محتواش رو درک کنه، ایندکس کنه.
در این شرایط، معمولا لینک های زیادی به صفحه مسدود شده وجود داره، بنابراین گوگل تحریک میشه که بدون خزیدن اون صفحه رو ایندکسش کنه.
لینک ها به امتیاز رنک پیج تبدیل میشن. گوگل اون رو محاسبه میکنه تا ارزیابی کنه که آیا صفحه مهمه یا نه. الگوریتم PageRank لینک های داخلی و خارجی رو در نظر میگیره.
وقتی لینک سازی سایتتون بدون استراتژی انجام بشه و گوگل ببینه که یه صفحه غیرمجاز دارای ارزش PageRank بالایی هستش، پیش خودش فکر میکنه که صفحه خیلی مهمه و باید حتما اون رو توی صفحه SERP نشون بده.
با این حال، این ایندکس فقط یه URL خالی بدون اطلاعات محتوا رو ذخیره میکنه زیرا محتوا خزیده نشده.
چرا Indexed, though blocked by robots.txt برای سئو سایت بد است؟
وضعیت Indexed, though blocked by robots.txt یه مشکل جدی محسوب میشه. ممکنه از نوع خوش خیم به نظر بیاد، اما سئو سایتتون رو به دو دلیل خراب میکنه:
⛔ظاهر ضعیف در نتایج جستجو
اگر یه صفحه رو به اشتباه مسدود کردید، Indexed, though blocked by robots.txt به این معنی نیست که خوش شانس بودید و گوگل خطای شما رو تصحیح کرده.
صفحاتی که بدون خزیدن ایندکس میشن، توی نتایج جستجو ظاهر جذابی ندارند، چونکه گوگل نمیتونه این موارد رو نمایش بده:
✨تگ عنوان (خودش یه تگ عنوان درست میکنه از URL صفحه و اطلاعاتی که در صفحاتی که بهش لینک دادند هست)،
✨توضیحات متا
✨هر گونه اطلاعات اضافی در قالب نتایج غنی
بدون این عناصر، کاربران نمیدونند پس از ورود به صفحه چه انتظاری باید داشته باشند و ممکنه وبسایتهای رقیب رو انتخاب کنند و در نتیجه CTR شما به شدت کاهش پیدا میکنه.
اینم یه مثال از محصولات خودِ گوگل:
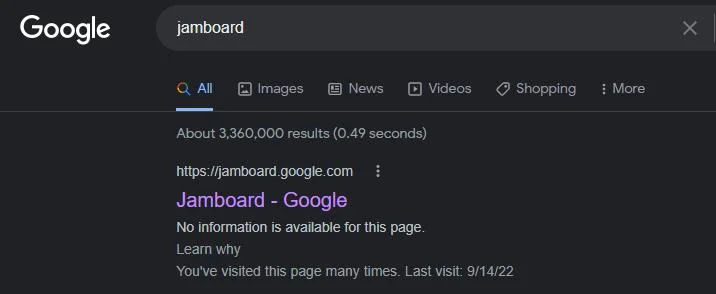
Google Jamboard از خزیدن مسدود شده، اما با نزدیک به ۲۰۰۰۰ بک لینک از سایر وب سایت ها (طبق گفته Ahrefs)، گوگل همچنان اون رو ایندکس کرده.
درسته که این صفحه رتبه بندی شده اما هیچ گونه اطلاعات اضافی در اون نمایش داده نمیشه، چونکه گوگل نمیتونه اون رو بخزه و اطلاعاتی برای نمایش جمع آوری کنه. فقط نشانی وب و عنوان اصلی رو نشون میده که همونم از وب سایت هایی که بهش لینک دادند گرفته.
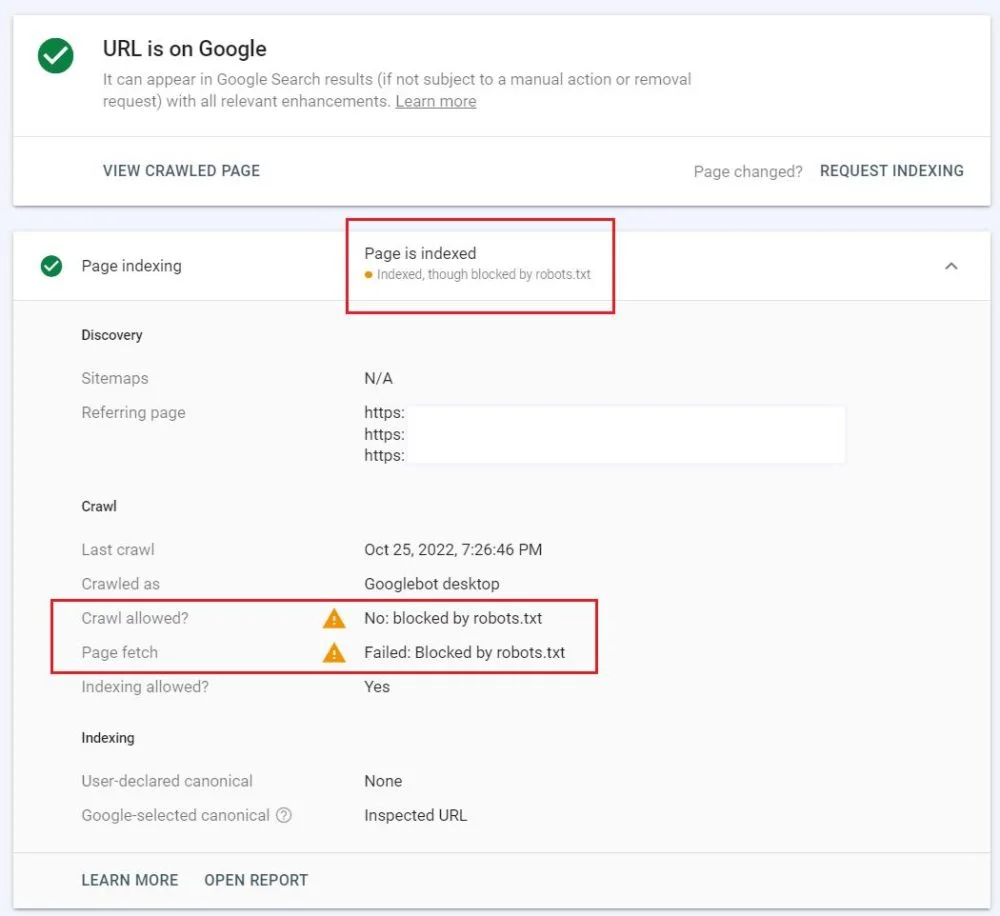
برای اینکه ببینید آیا صفحه شما هم همین مشکل رو داره و Indexed, though blocked by robots.txt هستش یا نه، به سرچ کنسول خودتون برید و از ابزار URL inspection استفاده کنید.
⛔ترافیک ناخواسته
اگر عمداً از دستور Disallow در فایل robots.txt برای صفحه خاصی استفاده کردید، نمی خواید کاربران اون صفحه رو در گوگل پیدا کنند. فرض کنید، مثلا، روی محتوای آن صفحه کار می کنید و برای نمایش عمومی آماده نیست.
اما اگه صفحه ایندکس بشه، کاربران میتونند اون رو پیدا کنند، واردش بشن و در نتیجه نظر منفی در مورد وب سایتتون خواهند داشت.
روش رفع خطای Indexed, though blocked by robots.txt در گوگل سرچ کنسول
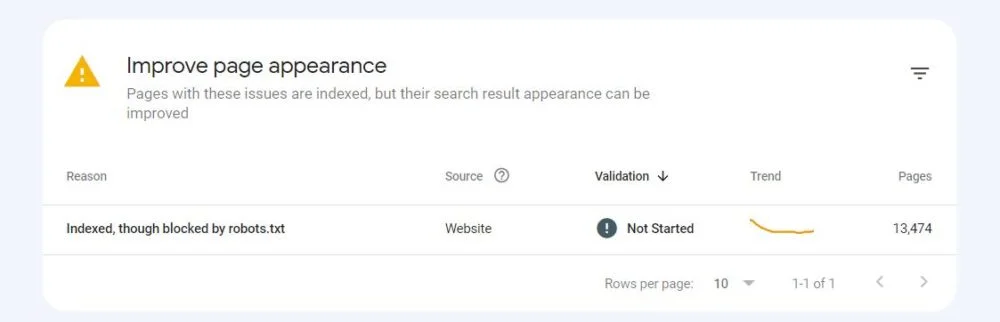
ابتدا وضعیت Indexed, though blocked by robots.txt رو در پایین گزارش Page indexing در گوگل سرچ کنسول خود پیدا کنید.
در اونجا جدول “Improve page appearance” رو مشاهده خواهید کرد.
پس از کلیک بر روی وضعیت، لیستی از URL های تحت تأثیر و نموداری رو مشاهده خواهید کرد که نشون میده تعداد اونها در طول زمان چه تغییری کرده.
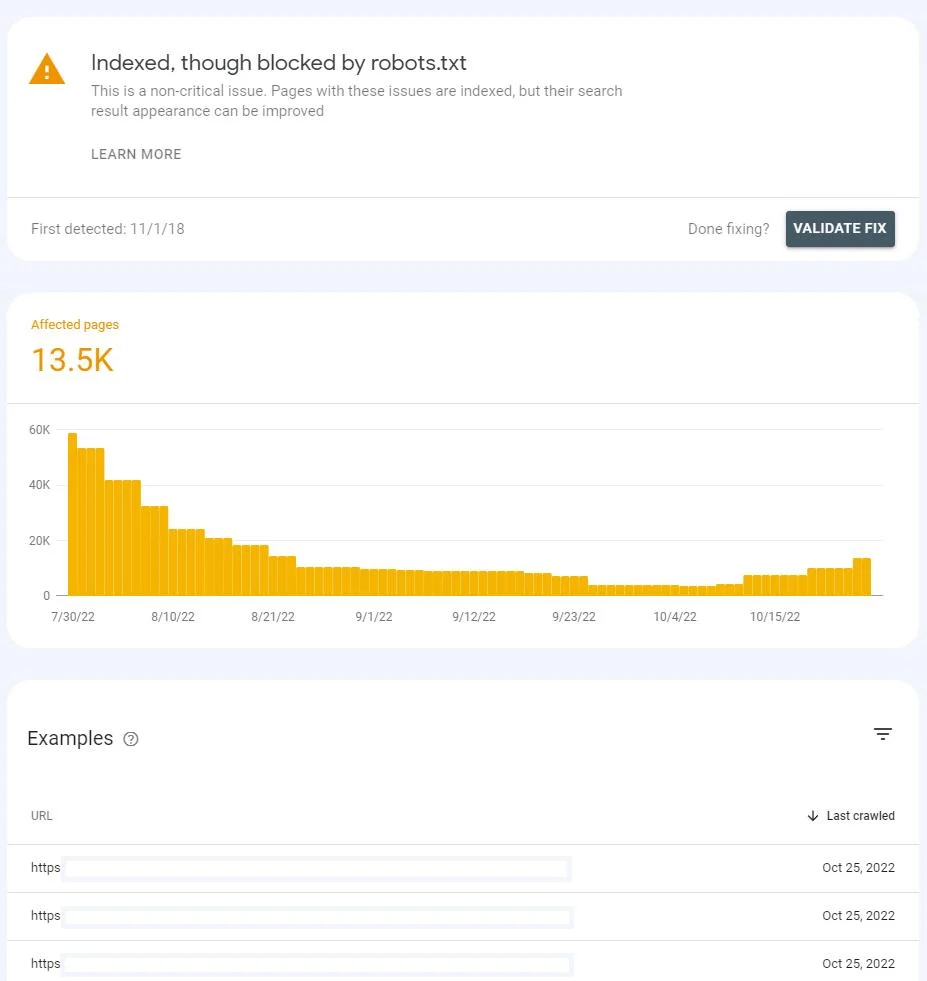
لیست رو میتونید با URL یا مسیر URL فیلتر کنید. وقتی آدرس های زیادی دارید که تحت تاثیر این مشکل قرار گرفتند و فقط می خواید برخی از قسمت های وب سایت رو بررسی کنید، از نماد هرم در سمت راست استفاده کنید.
قبل از شروع عیب یابی، در نظر بگیرید که آیا URL های موجود در لیست واقعاً باید ایندکس بشن یا نه. آیا حاوی محتوایی هستند که میتونه برای بازدیدکنندگان شما ارزشمند باشه؟
زمانی که می خواهید صفحه ایندکس شود
اگه صفحه به اشتباه در robots.txt غیرمجاز شده، باید فایل رو تغییر بدید.
وقتی دستورالعمل Disallow که خزیدن URL رو مسدود میکنه حذف کنید، ربات گوگل دفعه بعد که از وب سایت شما بازدید میکنه، اون رو میخزه.
زمانی که می خواهید صفحه ایندکس نباشد
اگه صفحه حاوی اطلاعاتی باشه که نمیخواید کاربران از طریق موتور جستجو ببینند، باید به گوگل بگید که نمیخواید ایندکس بشه.
فایل Robots.txt نباید برای کنترل ایندکس استفاده بشه. این فایل از خزیدن ربات گوگل جلوگیری میکنه. برای کنترل ایندکس باید از تگ نوایندکس استفاده کنید.
⛔باید حتما به گوگل اجازه بدید که صفحه رو بخزه تا بتونه این تگ رو ببینه.
اگه تگ noindex رو اضافه کنید اما صفحه رو در robots.txt مسدود نگه دارید، گوگل تگ رو پیدا نمیکنه و صفحه “Indexed, though blocked by robots.txt ” باقی میمونه.
وقتی گوگل صفحه رو میخزه و تگ noindex رو میبینه، در نتیجه صفحه رو از صفحه نتایج برمیداره.
حواستون باشه که اگه میخواید هر صفحهای رو از گوگل و کاربران دور نگه دارید، همیشه امنترین انتخاب برای اجرای احراز هویت HTTP روی سرور هستش. به این ترتیب فقط کاربرانی که وارد سیستم میشن میتونند بهش دسترسی داشته باشند. برای مثال، اگه می خواید از داده های حساس محافظت کنید، حتما اینکارو انجام بدید.
راه حل برای دراز مدت
راهحلهای که برای مشکل Indexed, though blocked by robots.txt گفتم برای مدتی کارتون رو راه میندازه. با این حال، ممکنه در آینده برای صفحات دیگه ای هم این خطا پیش بیاد.
چنین وضعیتی نشون میده که وب سایت شما ممکنه به لینک سازی داخلی بهینه یا بهبود استراتژی بک لینک نیاز داشته باشد.
خطای Blocked by robots.txt در گوگل سرچ کنسول یعنی چه؟
خطای Blocked by robots.txt نشون میده که گوگل صفحه رو نخزیده چونکه با دستور Disallow در robots.txt مسدودش کردید. همچنین به این معنیه که URL ایندکس نشده.
جلوگیری از خزیدن در برخی از URL ها طبیعیه، مخصوصاً وقتی وب سایتتون بزرگ باشه. کلا برخی از صفحات نباید توی نتایج جستجو نشون داده بشن.
تصمیم گیری در مورد اینکه چه صفحاتی باید یا نباید در وب سایت شما خزیده بشن، یک مرحله حیاتی و مهم در ایجاد استراتژی ایندکس هستش.
روش رفع خطای Blocked by robots.txt
ابتدا به جدول “Why pages aren’t indexed” در گزارش page indexing برید و خطای Blocked by robots.txt رو پیدا کنید.
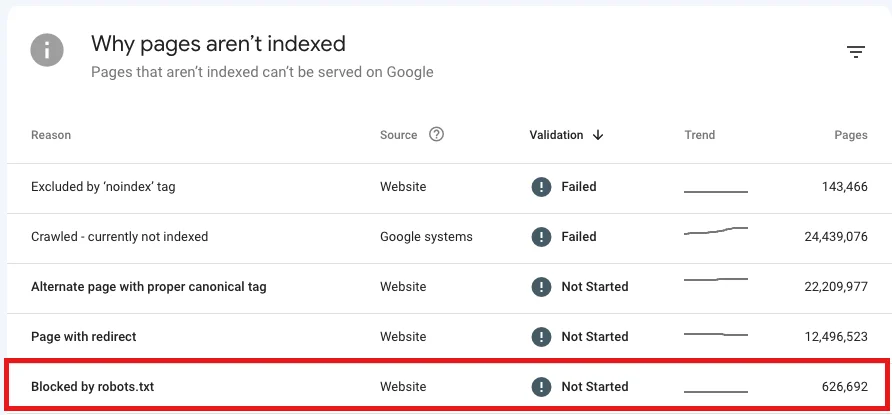
پرداختن به این مشکل نیازمند دو تا رویکرد متفاوت هستش:
❶وقتی که میخواید صفحه ایندکس بشه
❷وقتی که نمیخواید صفحه ایندکس بشه
در ادامه بهتون میگم که در هر دو موقعیت باید چیکار کنید:
وقتی به اشتباه از دستور Disallow استفاده کردید
در این مورد، اگه میخواید خطای Blocked by robots.txt رو برطرف کنید، باید دستور Disallow که خزیدن صفحه رو مسدود میکنه، حذف کنید.
با اینکار، ربات گوگل به احتمال زیاد دفعه بعد که وب سایت شما رو بخزه اون صفحه رو هم میخزه. اگه مشکل دیگهای نداشته باشه، ایندکسش میکنه.
اگر URL های زیادی دارید که تحت تأثیر این مشکل قرار گرفتند، در گوگل سرچ کنسول فیلترشون کنید. روی وضعیت کلیک کنید و نماد هرم معکوس رو در بالای لیست URL رو انتخاب کنید.
میتونید تمام صفحات آسیبدیده رو بر اساس URL (یا تنها بخشی از مسیر URL) و آخرین تاریخ خزیدن فیلتر کنید.
این خطا همچنین ممکنه به این معنی باشه که شما عمداً کل دایرکتوری رو مسدود کردید اما ناخواسته صفحهای داخلش بوده که میخواید خزیده بشه. برای رفع این مشکل:
⛄تا جایی که میتونید قطعات مسیر URL رو در دستورالعمل Disallow قرار بدید تا از اشتباهات احتمالی جلوگیری کنید
⛄یا از دستورالعمل Allow استفاده کنید تا به ربات ها اجازه بدید یک URL خاص رو در این دایرکتوری بخزند.
هنگام تغییر robots.txt، حتما دستورالعملهاتون رو با استفاده از robots.txt Tester در گوگل سرچ کنسول چک کنید. این ابزار فایل robots.txt رو برای وب سایت شما دانلود میکنه و بهتون میگه که آیا فایل درست کار میکنه یا نه.
robots.txt Tester همچنین شما رو قادر میسازه بررسی کنید که چگونه دستورالعملهای شما بر یک URL خاص در دامنه برای یه User-agent معین، مثل ربات گوگل تأثیر میذاره. به لطف این تستر، میتونید با اعمال دستورالعمل های مختلف آزمایش کنید و ببینید آیا URL مورد نظر داخلش مسدود شده یا نه.
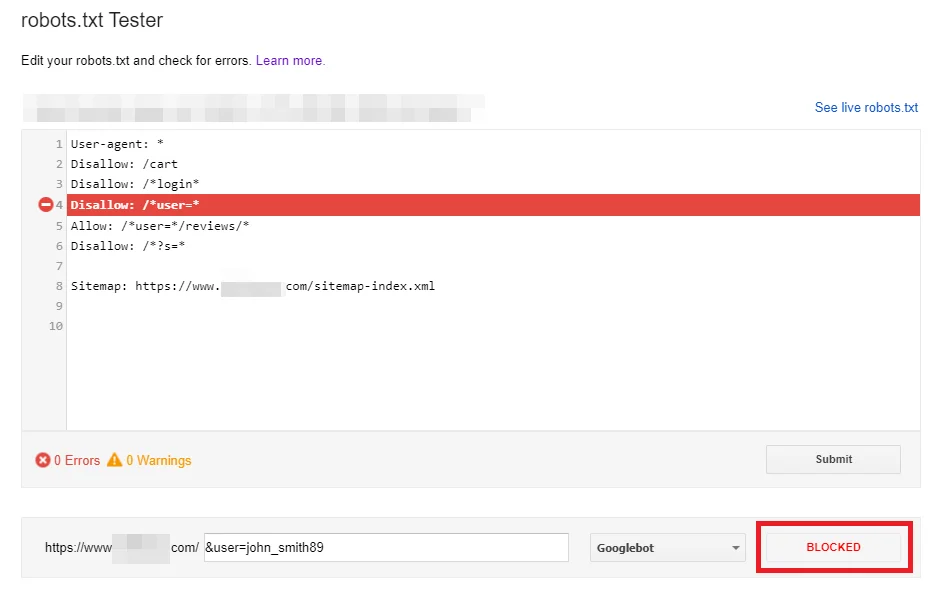
حواستون باشه که این ابزار به طور خودکار فایل robots.txt شما رو تغییر نمیدن. بنابراین، پس از اتمام آزمایش دستورالعمل ها، باید تمام تغییرات رو به صورت دستی در فایل پیاده سازی کنید.
علاوه بر این، توصیه میکنم از افزونه Robots Exclusion Checker در گوگل کروم استفاده کنید. این ابزار به شما امکان میده صفحات مسدود شده توسط robots.txt رو برای هر دامنهای که میخواید ببینید. باهاش URL های مسدود شده در دامنه خودتون رو بررسی کنید و روی آنها کار کنید.
اگر همچنان صفحات ارزشمند در robots.txt مسدود بمانند چه؟
به میزان قابل توجهی به ترافیک سایتتون در نتایج جستجو آسیب وارد میشه.
وقتی عمدا از دستور Disallow استفاده کردید
میتونید وضعیت Blocked by robots.txt در گوگل سرچ کنسول نادیده بگیرید تا زمانی که هیچ نشانی اینترنتی ارزشمندی رو در فایل robots.txt خودتون مسدود نکرده باشید.
یادتون باشه که مسدود کردن ربات ها از خزیدن محتوای کم کیفیت یا تکراری کاملا طبیعیه و در واقع برای سئو سایتتون خوب هم هست.
و تصمیم گیری در مورد صفحاتی که ربات ها باید و نباید بخزنند بسیار مهمه:
⚫یک استراتژی خزیدن برای وب سایت خود ایجاد کنید
⚫اینکار به طور قابل توجهی به شما کمک میکنه تا بودجه خزش خودتون رو بهینه کنید
جمع بندی
✍دستور Disallow در فایل robots.txt، گوگل رو از خزیدن صفحه مسدود میکنه اما بعضی وقتها نمیتونه جلوی ایندکس شدنش رو بگیره.
✍داشتن صفحاتی که هم ایندکس شدن و هم گوگل نمیتونه اونها رو بخزه برای سئو بده.
✍برای رفع Indexed, though blocked by robots.txt، باید تصمیم بگیرید که آیا صفحات آسیب دیده باید در جستجو قابل مشاهده باشند یا نه و سپس:
❖فایل robots.txt خود را تغییر دهید
❖در صورت لزوم از متا تگ noindex استفاده کنید
✍اگه نمیخواید ربات ها این URL ها رو بخزند و محتوای اونها رو ببینند، داشتن صفحات “Blocked by robots.txt” در وب سایت شما مشکلی به وجود نمیاره.
خزیدن و ایندکس اساس سئو هستند و یک فایل robots.txt به خوبی سازماندهی شده تنها بخشی از اون محسوب میشه.
در این مقاله در مورد خطای Blocked by robots.txt صحبت کردیم. ممنون که تا انتهای مقاله همراه من بودید در صورتی که حس میکنید مطلبی هست که گفته نشده حتما در قسمت نظرات با ما به اشتراک بگذارید. در صورت داشتن هرگونه سوال با تیم پشتیبانی پارس اوستا در ارتباط باشید.
سلام ، وقت بخیر
add to cart و add to whishlist باید تو فایل robots.txt محدود بشن ؟ یعنی Disallow بشن ؟
.
یا باید تگ نوایندکس داشته باشن؟
سلام ساناز ممنون از وقتی که گذاشتی. بله برای مسدود کردن این URLها، میتونی از دستورات زیر در فایل robots.txt استفاده کنید:
User-agent: *
Disallow: /*add_to_cart*
Disallow: /*add_to_wishlist*